Website URL
https://gifyu.com
Chevereto version
3.10.18
Description of the issue
I have recently started seeing an increase in timeout errors on my site. This is when doing a search or listing more than 250 images at once. Also when uploading more than 10 images some of it fails.
Usually, I do a PHP service restart or do a complete server reboot to fix. However, past few days it is repeating very often. If I am correct this issue started when the expire image setting kicked in early this month. Hence 1000s of images are deleted automatically every day.
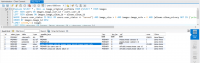
Nginx logs have several of below errors. However, PHP error log is clean without any entry for several days. CPU and RAM usage for the server is below 50%.
I tried server fault and advise were to check PHP error logs which are empty in my case.
Could you point me in the right direction to investigate this further?
https://gifyu.com
Chevereto version
3.10.18
Description of the issue
I have recently started seeing an increase in timeout errors on my site. This is when doing a search or listing more than 250 images at once. Also when uploading more than 10 images some of it fails.
Usually, I do a PHP service restart or do a complete server reboot to fix. However, past few days it is repeating very often. If I am correct this issue started when the expire image setting kicked in early this month. Hence 1000s of images are deleted automatically every day.
Nginx logs have several of below errors. However, PHP error log is clean without any entry for several days. CPU and RAM usage for the server is below 50%.
Code:
2018/08/22 10:05:30 [error] 1158#1158: *3202744 FastCGI sent in stderr: "PHP message: Request denied" while reading response header from upstream, client: 162.158.167.9, server: gifyu.com, request: "POST /json HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "gifyu.com", referrer: "https://gifyu.com/"I tried server fault and advise were to check PHP error logs which are empty in my case.
Could you point me in the right direction to investigate this further?